
Homework 0
Start on Jan 5, 2026 | Due on Jan 14, 2026
Homework Questions 0: Probability, linear algebra, and calculus
Out on Jan 5, 2026.
Posted on Crowdmark.
Programming Homework 0: Setup
Before getting started, note that homeworks are developed and best run on linux with a terminal. You should also be able to use MacOS and a terminal, but Windows is not recommended. If you only have a Windows machine and want to use that, you should install the Windows Linux Subsystem or a Linux Virtual Machine so that you can have a terminal for running your homework.
Setup group on Coursys
Find a group to work with for the homework assignments and the final course project. The group size should be 2 to 3 people. You can use Coursys Discussion Forum to look for teammates.
We will be checking that all group members are contributing equally to the homework submission and the final project.
Along with your group members, register yourself as part of a group on Coursys. Please make sure you use exactly the same group name. We will use Coursys for providing you feedback on the autograded portion of the homework.
Create a memorable name for your group. If you need help, seek help.
Selecting group names Please take care when selecting a group name and follow the guidelines below.
- Please choose a group name that is distinctive and unlikely to be used
by another group. For instance,
group,nlp-group,cmpt713,noneare all poor group names. - Do not use any obscene words in your group name. Be mature about your choice of group name. That does not mean it cannot be funny, just be aware that your choice of group name may offend someone else so be considerate of others.
- Do not use any strange characters in your group name.
Use alphanumeric characters [a-z0-9] only in your group name, underscore and dashes are also permited (please avoid spaces).
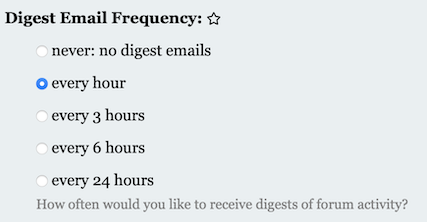
Go to the Coursys Discussion Forum and select [Activity Digest].
Change the Digest Email Frequency: to a setting that send you email notifications, like so:
Setup Git Repository
Git Basics
In this course, your programs will be managed and archived using Git. The basic idea is as follows:
- Every student and group gets a private storage area called a repository on the SFU server machines, or “repo” for short.
- Your code is stored in your repo. Every time you make a change to your code, you commit a new revision of your code to the repo for permanent storage. All revisions you ever commit are kept, and you can retrieve any committed revision any time. This means you have a combined backup and means to undo any changes you ever make. This is how software engineers manage their code projects.
Create new repository on SFU Github
Decide in your group the person that will create the repository on SFU Github and invite the other group members as a Collaborator (see below on how to add users to your repo). That main github owner (who created the github repo) should follow the instructions in this section.
Go to the SFU Github server which is on the web at github.sfu.ca. Log in with your SFU username and password, the same one you use to check your e-mail on the SFU Outlook mail server. You should enable 2FA if you have not done so already and also go through the 2FA authentication.
Once logged in, you will see a list of your existing repos if you
have created any in the past. Create a new Private repository for this class by going to https://github.sfu.ca/new.
From the UI, you can click the New Repository button (if this is your
first repository on SFU Github) or New button  (at the top right of the left panel).
(at the top right of the left panel).
On the Create a new repository page,
give your repo a name under the Repository name field.
You must name your repo: nlpclass-1261-g-GROUP where GROUP is the group you registered on Coursys. For example, a repository name might be nlpclass-1261-g-ethicsgradient Make sure you add the g- before
your group name. It’s important to name the repo exactly as you see
here.
Write an optional Description.
Make sure that you mark the repository at `Private’.
Important: You must choose this repository to be
Private. We will not accept any repository for the homeworks in this course that is marked asPublic. Your repo must be visible only to yourself and your group members. You must not give access to your repo to any other students except your group members, the TA(s) and the instructor..Plagiarism is a serious academic offense. At any point in the future you are also not allowed to either mark this repository as Public or copy the code to a different public repository (on Github or elsewhere).
Since we will be using Python, choose Python as the .gitignore template.
Leave all other settings as they are and click the Create repository button
at the bottom left of the page.
Your repo has now been created. You will be taken to the web page for your newly created repo.
We use an automated process to align your group name in Coursys to your repo in github. If your group name and repo does not match exactly, we will not be able to match your github repo to your Coursys group. If you used spaces in your group name in Coursys by mistake, make sure that your github repo has dashes (‘-‘) instead of spaces (because the internal system name used by Coursys will have dashes instead of spaces).
Add the instructor and TA and other team members as Collaborators
This is the most important step in the setup of your Github repository
The course instructor and the TAs need access to your repo in order to test
and grade your code.
Open the Settings page and click on the Collaborators (left panel) to add the instructor and TAs as a member of your repo.
On the access page that loads up, click on Add people in the Manage access and add angelx, sraychau, qiruiw, atw7, xsa55 and invite them as a Collaborator.
You should remember to add the other team members of the group as Collaborators as well. If they have not visit SFU Github before, they need to visit it so that their username become registered with SFU Github.
Set up notifications
You should be automatically set up to “Watch” changes to your repository, but ensure that you are watching changes.
Set up your notifications by going to your personal settings accessed through your user icon on the upper right corner:
Then select Notifications (with the bell icon) and make
sure you are notified about changes to the repository:
Make sure you are notified about Github Issues.
Setup SSH Key
Next we will set up the Secure Shell (ssh) keys so you can access your repo without a password.
First set up your SSH key pair.
You should check for existing keys and create new SSH keys if needed.
Use USER@sfu.ca as your email (where USER is your SFU username).
If you have set up your SSH key correctly then you will have a public key. To view it:
cat ~/.ssh/id_ed25519.pub
This will show you the public key. Use the Terminal copy command to copy this into your clipboard.
Now we have to copy your public key to the Github server.
Go to this page: https://github.sfu.ca/settings/keys and you will see a page for entering your SSH key.
Follow the instructions to copy and add your key to your github.
Click on New SSH Key and use the web browser to paste your public key into the Key box and give it a Title (e.g. ‘CSIL’ is a reasonable title if you are using CSIL) and then Add key.
Clone your Repository
Download a copy of your repo to your CSIL machine (see FAQ for how to access CSIL). The action of making a local copy of your online repo is known as a “clone”.
In the terminal window, enter the commands
git config --global user.name USER
git config --global user.email USER@sfu.ca
git config --global core.editor nano # or set it to your favourite editor
git config --global push.default current
cd $HOME
git clone git@github.sfu.ca:GROUPUSER/nlpclass-1261-g-GROUP.git
where USER is your SFU username, GROUPUSER is the SFU username of
the person who created the group repository and GROUP is the name of the
group you have already setup on Coursys. If
you skipped any of the above steps in setting up your GitHub repo
this command will not work. The system might prompt you for a
username/password combo. Supply the usual answers. To avoid entering
your username/password over and over again you can set up passwordless
ssh.
Your repo will be cloned into a new directory (also known as a folder)
called nlpclass-1261-g-GROUP.
Create your Homework 0 directory
After cloning your repository, make sure you are inside your repository and at the top level. Create a directory for Homework 0:
mkdir hw0
cd hw0
pwd
When you print your working directory it should look like this:
nlpclass-1261-g-GROUP/hw0
Add a file README.md to this directory using your favourite editor
and then git add README.md and git commit -m "Initial hw0 commit"
and then git push to send your new directory and file to the
Github server. Open up Github on a web browser to check that you
can see hw0/README.md in your repository on the web browser.
If you haven’t added a .gitignore file, make sure to add a .gitignore file at the top level of your git repository to avoid committing and pushing useless files to the GitHub server.
Here is a typical .gitignore file.
venv
__pycache__
.DS_Store
*.egg-info
.ipynb_checkpoints -->
Python 3 notebooks and virtualenv
We recommend the use of Python 3 notebooks and virtualenv to help with your development. You will also be submitting a self contained Python 3 program that can be run on the command line as well. We will be checking your code, and the Python notebook can be used to point out key parts of your code.
First set up a virtual environment to contain all the dependencies you need to run a Python3 notebook. To use virtualenv to manage dependencies, first setup a virtualenv environment:
python3 -m venv venv
source venv/bin/activate
pip3 install -U -r requirements.txt
The file requirements.txt should minimally have the following
contents.
pip
wheel
notebook
jupyter_contrib_nbextensions
jupyter_nbextensions_configurator
You can add more requirements by creating your own requirements.txt
file in the answer directory of each homework. Typically for
each homework you will add any additional software package requirements
you need into the requirements.txt file. These packages should
be already available on CSIL machines so the venv should not use
up too much disk space if you are using a CSIL machine.
If you have trouble, sometime clearing the pip cache helps. Remove
the contents of ~/.cache/pip before the pip install.
Run jupyter notebook:
jupyter notebook
Read the jupyter documentation and get used to editing a notebook with a combination of markdown and Python code.
Task: Segmentation into Words
Homework 0 is mainly to set up your groups and programming environment for this course for the semester, but to complete this homework you have to submit the solution to the following task as your submission for Homework 0. It will serve as a guide for the steps to be taken for all subsequent homeworks in this course.
The sample task for this homework is to automatically segment English input that does not have word boundaries into the most plausible sequence of words.
Submission for each homework will be done on Coursys.
Getting Started
Get started:
git clone https://github.com/angelxuanchang/nlp-class-hw.git
cd nlp-class-hw/ensegment
Clone your repository if you haven’t done it already:
git clone git@github.sfu.ca:GROUPUSER/nlpclass-1261-g-GROUP.git
where GROUPUSER is the SFU username of the person who created the group repository
and GROUP is the name of the group you have setup on Coursys.
Then copy over the contents of the ensegment directory into your
hw0 directory in your repository.
Set up the virtual environment:
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
Note that if you do not change the requirements then after you have
set up the virtual environment venv you can simply run the following
command to get started with your development for the homework:
source venv/bin/activate
Background
Given a URL: choosespain.com what is this website about?
You might guess one of the following alternatives:
choose spainchooses pain- etc.
Categorizing the website correctly involves segmenting the domain name correctly into the right sequence of words.
A similar situation arises in Twitter hashtags. What does
the hashtag nowthatcherisdead refer to? Again there
are some very different alternatives depending on the
segmentation:
now thatcher is deadnow that cher is dead
Your task is to use simple word counts to segment such examples into the most likely sequence of words.
Default solution
The default solution is provided in default.py. To use the default
as your solution:
cp default.py answer/ensegment.py
cp default.ipynb answer/ensegment.ipynb
python3 zipout.py
python3 check.py
Make sure that the command line options are kept as they are in
default.py. You can add to them but you must not delete any
command line options that exist in default.py.
Submitting the default solution without modification will get you zero marks.
The default solution scores each possible word segmentation. Each segmentation is scored based on the probability of the words that occur in that segmentation. If input is a sequence of characters (without word boundaries): \(c_0, \ldots, c_n\).
Let us define a word as a sequence of characters: \(w_i^j\) is a word that spans from character \(i\) to character \(j\). So one possible word sequence is \(w_0^3 w_4^{10} w_{11}^n\). We can score this sequence using word probabilities.
$$\arg\max_{w_0^i, w_{i+1}^j, \ldots, w_{n-k}^n} P_w(w_0^i) \times P_w(w_{i+1}^j) \times \ldots \times P_w(w_{n-k}^n)$$
The unigram probability \(P_w\) is constructed using the data
in count_1w.txt. The model is simple but the
search is over all possible ways to form word sequences for the
input sequence of characters. The argmax over all such sequences
will give you the baseline system. The \(\arg\max\) above can be computed
using the following recursive search over \(segment(c_0, \ldots, c_n)\):
$$\begin{eqnarray} segment(c_i, \ldots, c_j) &=& \arg\max_{\forall k <= L} P_w(w_i^k) \times segment(c_{k+1}, \ldots, c_j) \\ segment(\emptyset) &=& 1.0 \end{eqnarray}$$
where \(L = min(maxlen, j)\) in order to avoid considering segmentations of very long words which are going to be very unlikely. \(segment(\emptyset)\) is the base case of the recursion: an input of length zero, which results in a segmentation of length zero with probability \(1.0\).
To speedup the search, the default solution uses memoization of each \(segment\) in order to avoid the slow exploration of the exponentially many segmentations.
The Challenge
Your task is to improve the performance on this task as much as possible. The definition of performance is provided below. You cannot use any external data sources or any other toolkits. You can get a much higher performance by adding one simple function (one line of code) to the default solution provided to you. However this one line of code is not trivial. You should approach this challenge based on a careful examination of the source code of the default solution and the output of the default solution on the various inputs.
Background Reading
Read the following book chapter by Peter Norvig:
Just read the chapter for more insights into the challenge. Do not use any additional data available on the above page.
Data files
The data files provided are:
data/count_1w.txt– counts taken from the Google n-gram corpus with 1TB tokensdata/input– input filesdev.txtandtest.txtdata/reference/dev.out– the reference output for thedev.txtinput file
Required files
You must create the following files:
answer/ensegment.py– this is your solution to the homework. start by copyingdefault.pyas explained below.answer/ensegment.ipynb– this is the iPython notebook that will be your write-up for the homework.
Run your solution on the data files
To create the output.zip file for upload to Coursys do:
python3 zipout.py
For more options:
python3 zipout.py -h
Check your performance
To check your performance on the dev set:
python3 check.py
The score reported is F-score which combines precision and recall into a single score.
For this homework, tp (true positives) is defined as the words that were found in the output that exist in the reference. If a word occurs in the output but not in reference it is counted as a fp (false positive) and vice versa is counted as a fn (false negative). Precision \(p\) is defined as \(\frac{tp}{tp+fp}\). Recall \(r\) is defined as \(\frac{tp}{tp+fn}\).
F-score is defined as \(2 \cdot \frac{p \cdot r}{p + r}\).
For more options:
python3 check.py -h
In particular use the log file to check your output evaluation:
python3 check.py -l log
The output you will see is the score on the dev set:
$ python3 check.py
dev.out score: 0.82
The accuracy on data/input/test.txt will not be shown. We will
evaluate your output on the test input after the submission deadline.
The default solution gets a very poor F-score on the test set (again, you cannot see the test set score based on what is provided to you):
$ python3 check.py
dev.out score: 0.82
test.out score: 0.13
Using a single line function added to the default solution with no change to the input data files should get you remarkably higher F-score on both dev and test:
$ python3 check.py
dev.out score: 0.98
test.out score: 0.97
Note the scores above are just an example. Your scores may differ.
Preparing your python notebook to clearly document what you have done
You should prepare a clear summary of what you did in this assignment. For your documentation and analysis should be organized into clear sections, with grammatical English (full sentences). Use figures, graphs, tables to compare results of different experiments.
The documentation and analysis in your python notebook should include the following:
- A short description of the task (e.g. the problem you are solving) in your own words. In this case, you should describe what is English word segmentation. Make sure to indicate what is the expected input and output.
- Short description of your method
- Results (both quantitative and qualitative) comparing your method to the baseline (default) solution. For qualitative results, you should include some illustrative examples of the baseline vs your solution. For quantitative results, you would present tables/figures comparing how well the different methods performed (e.g. report and compare the F-score of the baseline and your method).
- Discussion of alternative methods you tried and how well they worked (or didn’t work).
Submit your homework on Coursys
Once you are done with your homework submit all the relevant materials to Coursys for evaluation.
Create output.zip
Once you have a working solution in answer/ensegment.py create
the output.zip for upload to Coursys using:
python3 zipout.py
Create source.zip
To create the source.zip file for upload to Coursys do:
python3 zipsrc.py
You must have the following files or zipsrc.py will complain about it:
answer/ensegment.py– this is your solution to the homework. start by copyingdefault.pyas explained below.answer/ensegment.ipynb– this is the iPython notebook that will be the documentation of what you have done and guide for your code for the homework.
In addition, each group member should write down a short description of what they did for this homework in answer/README.username.
Upload to Coursys
Go to Programming Homework 0 on Coursys and do a group submission:
-
Upload
output.zipandsource.zipto Coursys - Make sure you have documented your approach in
answer/ensegment.ipynb. - Make sure each member of your group has documented their contribution to this homework in
answer/README.usernamewhereusernameis your CSIL/GitHub username.
Grading
The grading is split up into the following components:
- Group setup done on Coursys.
- Github setup including adding instructor and TAs as Collaborator to the repository.
- dev scores (see Table below)
- test scores (see Table below)
- documentation and analysis (e.g. report) quality
- code content and quality (a good iPython notebook can help TAs understand your code)
- check if each group member has a
answer/README.username.
Your F-score should be equal to or greater than the score listed for the corresponding marks.
| F-score(dev) | F-score(test) | Marks | Grade |
| .82 | .13 | 0 | F |
| .84 | .50 | 55 | D |
| .85 | .55 | 60 | C- |
| .87 | .60 | 65 | C |
| .89 | .70 | 70 | C+ |
| .91 | .75 | 75 | B- |
| .93 | .80 | 80 | B |
| .95 | .85 | 85 | B+ |
| .97 | .90 | 90 | A- |
| .98 | .95 | 95 | A |
| .99 | .97 | 100 | A+ |
The score will be normalized to the marks on Coursys for the dev and test scores.